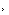|
dotamh,表示的是MMIO(内存映射)的范围,这个范围是通过PCI配置寄存器读出来的,Windows里,在驱动里用HalGetBusData可以获得,用户态好像没有直接访问的方法。
其中你能看到的属性里的那些描述,都是Base Address Registers里的东西。
I/O范围,表示的是I/O端口号,如果你熟悉汇编,你就知道汇编里有IN/OUT指令,这个I/O范围指的就是操作这个设备使用IN/OUT指令时的端口范围,这个范围跟内存就没什么关系了。有些I/O范围也写在PCI配置里,但是没有严格的规定。
因为显卡厂商一般不太愿意公开这方面的信息,从我看到的一些资料上看,各个厂商对MMIO映射的地址空间的描述也完全不同,没有任何规范可言。
如果能拿到厂商的白皮书的话,也许还好办,但显卡厂商出于保密原因一般不给这方面的资料。
1) 操作显卡的寄存器映射,用于发送控制命令,你的图里的那128K可能就是这个用途,这类地址一般都可以直接读写;
2) 映射显卡的一部分显存(注意不是全部),你的图里的那256M可能就是这个用途,这类地址读写的特性不确定。
写之前可能会通过I/O端口或者其它MMIO地址去操作显卡寄存器发送一部分控制命令,具体是什么就不清楚了,厂商一般都保密。
Windows应该采取的是类似的动作,Frame Buffer就是你截图里的那256M的一部分。
你截图肯定不全,滚动条向下,你还能找到更多的MMIO内存地址范围,但一般情况下,不会把全部显存都映射过去。
原因是显存可能很大,这么做太浪费地址空间,对于32位系统来说,地址空间实在有限。
那么CPU是如何通过256M地址空间访问1G的显存的?原因是256M只是一个窗口,它可以把显存的某一段映射到内存中去,如果CPU要操作其它的位置,就发送控制命令改变映射的范围即可。
MMIO映射空间小于实际显卡显存,有些时候是为了刷新更多帧的需要,以题主你自己的显卡为例,可以先映射1G空间里的第一个256M,把要显示的图像写进去,再映射第二个256M,把后面要显示的图像写进去……以此类推,这样就能操作完整的显存了,甚至这么做可以提前把未来要绘制的图像先写到显存里。
不同的显卡每次能映射的最大显存数是不同的,可能是显卡本身DMA的限制,或者显卡本身处理能力有限,毕竟一次传输完一个完整显存大小的数据对于显卡来说负担还是太大了。
你可以去了解一下PCI驱动的开发,但这方面真的没有书可以推荐,因为显卡技术涉及到的保密内容太多,其中很多东西甚至没有专利,只有一些小厂商公开了一部分2D加速的技术资料,但具体如何操作寄存器,如何渲染图像,资料实在太难找。
的一些解释我不是特别认同,说CPU不能直接访问显存这个问题,我觉得说法不太严谨。
一般来说,Linux里都是用Frame Buffer驱动来向显卡写数据的,Frame Buffer最终是把数据送到显存里,这个过程是可以直接操作显存的,只不过这个“操作”的概念很模糊,因为有些是用DMA把数据传走的,如果说不能直接访问,也不对,至少DMA控制器是看见这部分显存了,只不过直接用CPU的指令MOV肯定会失败。
如果是频繁的刷新图像,可能会有一个专门的线程不停的向MMIO映射的那部分显存里做DMA,目的就是不停的刷新显存,让显卡那边图像更新。
统一编址的用途是给DMA控制器做DMA的时候用的,否则DMA操作起来会很麻烦。所以,严格的说,看具体什么样的显卡,有些显卡的显存是可以被CPU直接访问的,有些是不能的,但所有显存都是可以被DMA的。
显卡的具体操作技术都是保密的,很多显卡驱动也都是闭源的,包括在Linux上(有办法可以规避GPL),显卡的3D加速之类的具体如何操作硬件,基本上不会有厂商公布,所以对外表现出来的这些特性只能猜。
一些有合作的企业会公布一些代码,但看代码有时候很难理解它的行为,所以不要指望说看几本书就会写显卡驱动,很不现实,要做显卡驱动最好是到显卡厂商那边去。
在虚拟机里写一个简单的驱动,工作在内核态,然后找到显卡的MMIO的第一段地址,在驱动里加一段代码去读这个地址,结果发现这段地址上的数据正好就是屏幕上显示的像素信息。
因为是读的前4个int,所以用截图键(print screen)截图比较了一下,像素点像素值完全等于我通过debug打印的数值,这说明0xE8000000这个地址就是我虚拟机上的显存地址。
屏幕显示似乎没有变化,但通过截图键截图发现,屏幕的上面有一条黑线,正好是我ZeroMemory的位置:
这说明至少虚拟机里显卡映射的这部分是肯定可以读写的,甚至会影响系统截图的效果。
1. 内存和显存统一编址是指UMA,多用于核显。譬如Intel的核显,它没有自己独立的内存,必须和CPU共享内存。BIOS可以为核显在memory training后划分独立的空间,叫做stolen memory, 偷来给核显用,大小可以通过BIOS设置。
2. 被划分的核显内存通过GTT来索引,GTT类似页表。Frame Buffer也通过GTT来访问。
题主问的是windows系统,我不懂,不敢说。Linux略知一二,写过几年Linux的显卡驱动。但显卡驱动实在是太复杂了,这儿写不下,只能简单说一说,具体还是得查资料才能明白。好在设备驱动其实原理都差不多,相信能有一点帮助。
古代的显卡就不去提它们了,只说现代的。一块PCIe显卡,首先是个PCIe设备,要理解CPU如何操作显卡,首先得对PCIe设备的操作有些基本概念。需要的知识主要是:
2.CPU配置设备的过程。一般来说,是到总线上扫一下(Enumerate)看看,找到设备之后,按照规定去检测(probe)、初始化(init)。最开始的配置工作,是在配置空间做的,这个配置工作可以设置好I/O空间,以及别的一些基础工作。之后,CPU就可以通过I/O来更加方便地操作设备了。这篇维基百科可以参考:
***2.CPU是如何访问显存的(拿写为例子),是通过物理地址直接访问(如果上面256M是映射的显存的话);还是通过控制寄存器间接访问,即先把要写的数据放到寄存器,再发出命令让显卡取走,最后显卡把来自寄存器的数据写入显存。***
首先CPU不会通过物理地址直接访问现存。物理地址是什么?是相对于逻辑地址和虚拟地址来说的,只用来访问系统内存。而显卡的现存,是在设备之中的,CPU无法直接给出其物理地址。实际上现代的显卡一般都自己带一个MMU,做内存管理用的,CPU可以配置显卡的MMU,但无法直接访问它。
好吧其实也不绝对,因为不少移动设备的显卡并不是独立的,只是作为SoC的一个core(即GPU)存在,虽然也号称有显存,其显存却是由BIOS从系统内存中划分出固定的一块出来给它。于是乎,CPU是可以用物理地址访问显存的。这时候,CPU的MMU把一段虚地址空间映射到某一段物理内存上,GPU的MMU也把一段虚地址空间映射到同一段物理内存上,然后两边可以各自访问,比如CPU写了一段数据进去,然后让GPU去渲染显示。甚至CPU写了一段代码进去,请GPU去执行,即可以是3D渲染任务,也可以是利用GPU做一些加速运算。
所以说,一般CPU不直接访问显存。但在3D加速、GPGPU等场景中,有时是CPU和GPU共享一段物理内存,此时数据传输主要通过内存,而寄存器主要是传递控制命令用的。需要注意的是,3D加速、OpenCL、CUDA等场景下一般也是不共享内存的,而是从系统内存把数据和程序传输到显卡中、运行之、最后将结果传输回系统内存。
***3.很多人说显存的地址和内存的地址是统一编址的,那么CPU就可以直接访问显存,而不是通过控制器接口间接访问。我认为这是不对的,原因如下:我的显卡是1G的,但是下图显示只有256M地址空间分配给了显卡。***
显存地址和内存地址统一编址,这个概念很含糊,一般可以算错。然而还是有例外,具体请查Aperture Graphics Memory这个概念,但这东西比较古老,学习意义不大。
但是题主觉得显存是1G,而显示只有256M空间分配给了显卡,所以显存和内存地址一定不是统一编址的,这个逻辑也比较混乱。具体而言又不知从何说起,感觉题主对CPU如何访问内存还不是很清楚,这个需要翻一翻计算机体系结构的教材。然后也参考一下设备驱动开发的入门资料吧,Linux有Linux Device Driver,Windows我就不清楚了。
声明:上述内容大多数是凭模糊的记忆写的,相信有不少错误,欢迎指正。论文还没写完,暂时没时间查证,也许以后会更新完善。谢谢阅读!
256MB是线KB是windows模拟出来的DOS环境下的显存,以前这个地址是从A0000开始,到BFFFF结束
256并不是内存,而是控制端口,是《设备寄存器》,通过CPU指令《IN AL, DX》指令和《OUT DX, AL》指令操作的
三星990 PRO一直是深受用户青睐的一款高性能SSD,三星原厂主控和TLC闪存,PCIe 4.0性能拉满,不过它一直只有1TB、2TB容量。
|
 返回首页
返回首页 
 栏目文章
栏目文章