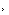|
贾继海这两者都是在3.1T token中英文数据上进行的预训练,Yi-9B则在此基础上,增加了0.8T token继续训练而成。
开头提到,Yi-9B最大的进步在于数学和代码,那么这俩能力究竟如何提升呢?
靠的是先增加模型大小,在Yi-6B的基础上增至9B,再进行多阶段数据增量训练。
Yi-6B训练得已经很充分,再怎么新增更多token练效果可能也不会往上了,所以考虑扩增它的大小。(下图单位不是TB而是B)
对原模型进行宽度扩增会带来更多的性能损失,通过选择合适的layer对模型进行深度扩增后,新增layer的input/output cosine 越接近1.0,即扩增后的模型性能越能保持原有模型的性能,模型性能损失微弱。
依照此思路,零一万物选择复制Yi-6B相对靠后的16层(12-28 层),组成了48层的Yi-9B。
实验显示,这种方法比用Solar-10.7B模型复制中间的16层(8-24层)性能更优。
然后增加另外的0.4T数据,同样包括文本和代码,但重点增加代码和数学数据的比例。
(悟了,就和我们在大模型提问里的诀窍“think step by step”思路一样)
即从固定的学习率开始,每当模型loss停止下降时就增加batch size,使其下降不中断,让模型学习得更加充分。
实测中,零一万物使用greedy decoding的生成方式(即每次选择概率值最大的单词)来进行测试。
(两者命名准则不一样,前者只用了Non-Embedding参数,后者用的是全部参数量并向上取整)
|
 返回首页
返回首页 
 栏目文章
栏目文章