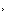|
�������з�19¥���ϰ�� RTX 30 ϵ���Կ� 9 �� 17 �վ�Ҫ�����ˣ�������Ҫ��ô�� GPU���ܼ��ܹؼ���
������ 9 �� 2 ��RTX 30 ϵ�з���ʱ��Ӣΰ�����������Կ��������Ϻ�Ч���ϵ����ƣ����ư�����Գ���ͼ��ܹ�һ��������һ���棬���� 3090 ֮�⣬��һ���Կ����Դ濴�������е㲻�������� AI ѵ��ʱ����һ���Կ�Ч��������Σ�
�������գ������õ���˹̹����UCL��CMU��NYU��UW ��ʿ offer��Ŀǰ�ڻ�ʢ�ٴ�ѧ������֪�����ⲩ�� Tim Dettmers ������һƪ�����£������ѧϰ��ҵ�����ѡ�� GPU ���������Ŀ�����
����������֪�����ѧϰ��һ���ܳ��������������ԣ�GPU ѡ�úò���ֱ�Ӿ���������������顣��ô����Щָ���������� GPU ʱӦ�����ӵ��أ�RAM��core ���� tensor core���������һ�����Լ۱ȵ�ѡ���ı����ص�������Щ���⣬ͬʱָ��һЩѡ��������
����RTX 3070 �� 2080Ti����������𣿲������Ѿ�������һ�����ܶԱ�ͼ���ı�����������
���������� Tensor Core�������������ڼ���˷��ͼӷ�ʱ��ʱ�����ڽ��� 1/16�������ظ������ڴ���ʣ��ü��㲻�������������е�ƿ����ƿ������˻�ȡ���ݵ��ٶȣ������ڰ���ܹ�һ����������˿����õ���� Tensor Core ���Կ��ˡ�
������Ϊ�������������ԣ��Դ���ʹ�� Tensor Core ���о���˷������ڳɱ�������Ҫ�IJ��֡�����˵������Ҫ��ע�IJ������ڴ������Bandwidth����������Լ���ȫ���ڴ���ӳ٣����ǿ��Խ�һ��ӵ�и���� GPU��
��������Ԥ�������䱸 Tensor Core �� GPU �ܹ�֮��IJ�����Ҫ�����ڴ�����������������Թ����ڴ� / L1 �����Լ� Tensor Core �и��õļĴ���ʹ��Ч�ʣ�Ԥ����������ΧԼ�� 1.78-1.87 ��֮�䡣
������ʵ��Ӧ���У�ͨ�� NVLink 3.0��Tesla A100 �IJ���Ч����Ҫ�� V100 ���� 5%�����ǿ��Ը���Ӣΰ���ṩ��ֱ�������������ض����ѧϰ�����ϵ��ٶȡ��� Tesla V100 ��ȣ�A100 ���ٶ������ǣ�
�����������ڼ�����Ӿ�������˵���¼ܹ���������Բ����ԡ����������ΪС�����ߴ硢������˷�������������� GPU �����ء�Ҳ�����������ض��ܹ����������������µĽ������ Transformer �ϣ�Ԥ����������ʵ���������dz��ӽ������������Ϊ���ڴ��;�����㷨�dz������ǿ���ʹ����Щʵ��Ч�������� GPU �ijɱ���Ч�ʡ�
������Ȼ���ڷ�������Ӣΰ������ָ��������ܹ���ϡ�������ѵ�������ٶ�������һ����ϡ��ѵ��ĿǰӦ�ý��٣�����δ����һ�����ơ���������µĵ;����������ͣ����ʹ�;��ȸ������ף�����һ������ǰ�� GPU ���졣
����Ӣΰ�ﻨ�Ѵ���������������һ�� RTX 3090 �ķ�����ƣ����������ܺã�����������Ч����λ�Ҫ�����ʺš����κ������ˮ�䶼��Ч�����õķ����������Ҫ���� 4 �� GPU������Ҫע��ˮ��Ľ�������������ǿ��ܻ���������ɢ���������һ�ַ����ǹ��� PCIe ��չ�������ڻ�����ԭ�Ȳ����ܵ�λ�÷� GPU����dz���Ч����ʢ�ٴ�ѧ��������ʿ�о��������߱���ʹ�����ַ�����ȡ���˳ɹ�������������Ư�������ǿ�������� GPU ������ˬ��
����4 �� RTX 2080Ti ��ʼ�� GPU ��װ������Ȼ����������һ�ţ�����������û�����⡣
�������е�Դ���⣬RTX 3090 ��һ�� 3 ��� GPU������ڲ���Ӣΰ��Ĭ�Ϸ�����Ƶ�����£��㲻���� 4x ��������ʹ���������Ǻ�������ģ���Ϊ���ı������� 350W��ɢ��ѹ��Ҳ����RTX 3080 �� 320W TDP ѹ��ֻ������Сһ�㣬��Ҫ��ȴ 4 �� RTX 3080 Ҳ���dz����ѡ�
������ 4x RTX 3090 ������£������Ϊ 4x 350W = 1400W ��ϵͳ�ҵ��ܺõĹ��緽ʽ��1600W �ĵ�Դ�������ԣ������ѡ�� 1700W �� PSU�����Ͼ�����ѫ�ڷ�����ϣ����������� RTX 3080 װ�� 700W �ĵ�Դ��Ȼ��Ŀǰ�����ϲ�û�г��� 1600W ��̨ʽ���Ե�Դ����ÿ��Ƿ��������߿�� PSU �ˡ�
������ͼչʾ�˵�ǰ���ŵ� Nvidia �Կ������ѧϰ��������ܱ��֣��� RTX 2080 Ti Ϊ�ԱȻ�������ͼ�п��Կ�����A100��40GB�������ѧϰ���������Ϊǿ������ RTX 2080 Ti �������ࣻ�³��� RTX 3090��24GB���ŵڶ����� RTX 2080 Ti �� 1.5 �����ҡ����Ƚ����ĵ��ǣ�RTX 3090 �ļ۸�ֻ���� 15%��
������������ͼ���˵��Կ�ȷʵ���㣬����ͨ�˸����ĵĻ����Լ۱ȣ�Ҳ����һ��Ǯ�������������������������֮ǰ��������һ�¸�������Ĵ����ڴ�����
������ͼ�Ǹ��ݸ��� GPU ������ѷ��eBay �ϵļ۸�������������а�����ġ�ÿһ��Ԫ�� GPU ���ܡ���
����ͼ 4���� RTX 3080 Ϊ������Ϊ 1�������� GPU ��ÿһ��Ԫ�������У�4 �� GPU����
����ͼ 5���� RTX 3080 Ϊ������Ϊ 1�������� GPU ��ÿһ��Ԫ�������У�8 �� GPU����
������������ǿ��һ�㣺������ѡ�Ŀ� GPU������Ҫȷ�������ڴ��������������Ϊ�ˣ���Ҫ���Լ��������⣺
������Ҫ�� GPU ��ʲô���������μ� Kaggle ������ѧ���ѧϰ���� CV/NLP �о�������С��Ŀ��
������ѡ����� GPU ��ʲô����Ҫ���𣿱��磬�����Ҫ�� RTX 3090������˳���ذ���װ���ҵļ���������ҵĵ�Դ��������ɢ�������ܽ����
��������˵���������Ҫʹ��Ԥѵ�� transformer ���ͷѵ��С�� transformer������ڴ�����Ҫ�ﵽ 11GB�������Ҫ�� transformer ������о����ڴ�����ܴﵽ 24GB��������Ϊ��֮ǰԤѵ���õ���Щģ�ʹ����ڴ��кܸߵ�Ҫ�����ǵ�Ԥѵ�������õ��� 11GB �� RTX 2080 Ti����ˣ�С�� 11GB �� GPU ����������ijЩģ�͡�
��������֮�⣬ҽѧӰ���һЩ SOTA ������Ӿ�ģ�͵Ȱ����ܶ����ͼ��������� GAN�����Ǩ�ƣ�Ҳ�����ڴ��кܸߵ�Ҫ��
����RTX 3070 �� RTX 3080 ���ܶ���ǿ�����ڴ��е�С�����ںܶ������У���ȷʵ����Ҫ��ô����ڴ档
�����������ѧ���ѧϰ��RTX 3070 �����ѡ����Ϊ��ģ�ͻ�����ͼ����Сһ�����ѧ���ּܹ��Ļ���ѵ�����ɡ�
��������ԭ����������ԣ�RTX 3080 ������Ϊֹ�Լ۱���ߵ�ѡ����ԭ���������У����������ٵ�Ǯ�������ڴ档�����ԭ���������漰��������Kaggle ������Ϊ������˾����˼· / ģ�͡��Լ����о��������ʵ�顣RTX 3080 ����Щ���������ѡ��
����������Ҫ�쵼һ���о�ʵ���� / ��ҵ��˾������� 66-80% ��Ԥ��Ͷ�� RTX 3080 �ϣ�20-33% �����Ƴ�����ǿ��ˮ��װ�õ� RTX 3090��������Ϊ��RTX 3080 �Լ۱ȸ��ߣ����ҿ���ͨ��һ�� slurm ��Ⱥ������Ϊԭ�ͻ�����������ԭ�����Ӧ�������ݵķ�ʽ��ɣ�����Ӧ��ʹ�ø�С��ģ�ͺ�С�����ݼ���RTX 3080 ���ʺ���һ�㡣һ��ѧ�� / ͬ������һ���ܰ���ԭ��ģ�ͣ����ǾͿ����� RTX 3090 �������Ƴ���ģ�Ͳ�������չΪ�����ģ�͡�
������֮��RTX 30 ϵ���Ƿdz�ǿ��ģ�ֵ�ô����Ƽ���ѡ��ʱ��Ҫע���ڴ桢��ԴҪ���ɢ�����⡣������� GPU ֮����һ�� PCIe ��ۣ�ɢ����û������ġ�����RTX 30 ϵ����Ҫˮ�䡢PCIe ��չ������Ч�Ĺķ������
�������߱�ʾ����������������� RTX 3090 �����Ƽ���� GPU����Ϊ��δ�� 3-7 ���ڣ�����һ�ʼ�ձ���ǿ�����ܵ��Կ�������Ϊ��HBM �ڴ���δ��������֮���ƺ����ή�ۣ������һ�� GPU ֻ��� RTX 3090 ���������� 25% ���ҡ�δ�� 5-7 ���������� HBM �ڴ潵�ۣ�����ʱ��Ҳ�û��Կ��ˡ�
����������Щ��������û��ô�ߵ��ˣ����о����μ� Kaggle����������˾���������Ƽ�ʹ�� RTX 3080������һ�����Լ۱ȵĽ�����������ҿ���ȷ����������Ŀ���ѵ����
������������ RTX 3070 ����̫���ˣ�����ѡ��һ������ RTX 2070�����ڻ����������� RTX 3060���������ȷʵԤ�����ޣ�����ѡ���ٵȵȡ�
����GPU ��Ⱥ����Ƹ߶����������Ӧ�ó���������һ�� + 1024 GPU ��ϵͳ������������Ҫ�ģ�������û���ϵͳһ��ֻ�� 32 �� GPU���Ǵ��ֱ�Ͷ������������þ���һ���˷ѡ�
����һ������£�RTX �Կ�����ֹͨ�� CUDA ����Э������������ģ���ͨ����У���⡣�������Ӣΰ��ȡ����ϵ����Ѱ����⡣
��������㱻����ʹ�� RTX �Կ��������Ƽ�ʹ��װ�� RTX 3080 �� RTX 3090 �ı� Supermicro 8 GPU ϵͳ�����ɢ��û������� �ڵ�Ϳ��Ա�֤ԭ�͵� rollout���ر���������֤ 8x RTX 3090 �������ܹ���Ч��ȴ������¡�����������£������Ƽ�ʹ�� A100�������� RTX 6000 / RTX 8000����Ϊ A100 �Լ۱Ⱥܸߣ�Ҳ����DZ����
������������� GPU ��Ⱥ��ѵ���dz�������磬�����Ƽ�װ���� A100 �� NVIDIA DGX SuperPOD ϵͳ���� +256 GPU �Ĺ�ģ�£������÷dz���Ҫ�����������չ�� 256 �� GPU ���ϣ������Ҫһ���߶��Ż���ϵͳ��
������ TPU ϵͳ��ȣ�GPU ϵͳ����Ϊ���ѧϰģ�ͺ�Ӧ���ṩ���������ԣ��� TPU ϵͳҲ�����ƣ�������֧�ָ����ģ�Ͳ��ṩ���õ���չ��
������������ Tesla V100 �� A100����Ϊ�Լ۱Ȳ��ߣ������㱻�����λ��������Ӵ�� GPU Ⱥ����ѵ���dz�������硣
��������Ѿ�ӵ�� RTX 2080 Ti ����õ� GPU�������� RTX 3090 ����ûʲô���塣����� RTX 30 ϵ�е� PSU ��ɢ�����⣬���������������ĺô���Щ��������� 4x RTX 2080 Ti ������ 4x RTX 3090 ��Ψһԭ������ǣ����� Transformer �������߶���������ȥѵ��������о���
�����������һ������ RTX 2070 GPU����Ҳ�Ѿ��൱�����ˡ�����������ܵ� 8GB �ڴ�����ƣ���ôת����Щ�������µ� RTX 3090 ��ֵ�õġ�
�����û����� GPU �϶��кܶ�˽����������ĵط�������������������������ʴ��ܽᣬ��Ҫ�漰 PCle 4.0��RTX3090/3080 �Լ� NVLink �ȵȡ�
����һ����˵����Ҫ���������һ�� GPU ��Ⱥ����ôӵ�� PCle 4.0 �����ˡ��������һ�� 8x GPU ��������ôӵ�� PCle 4.0 Ҳͦ�õġ�������֮�⣬PCle 4.0 ��ûʲô�á�
����PCle 4.0 ����ʵ�ָ��õIJ��л������Լ���������ݴ��䡣�������ݴ��䲻���Ϊ�κ�Ӧ���е�ƿ�����ڼ�����Ӿ��������ݴ洢���Գ�Ϊ���ݴ��� pipeline ��ƿ�������� CPU �� GPU �� PCle ����ȴ�����Ϊƿ����
�������Զ��ڴ��������˵��PCle 4.0 ��û�б�Ҫ�ġ��� 4 �� GPU �����£�PCle 4.0 ֻ��ʵ�� 1%-7% �IJ��л�������
������ 4x ͨ·������ GPU ��ͦ�õģ��ر��ǵ���ֻ�� 2 �� GPU ʱ���� 4 �� GPU �����£�����������ÿ�� GPU ���� 8x ͨ·�����������ȫ�� 4 �� GPU �Ͻ��в��л����������� 4x ͨ·�����п��ܽ����ʹ�Լ 5%-10% �����ܡ�
��������Ҫһ��˫��۱�����߳���ʹ�� PCle ��չ�������˿ռ��⣬��Ӧ�ÿ�����ȴ�ͺ��ʵ� PSU����������еĽ�������ǻ�ȡ�����Զ���ˮ���·�� 4x RTX 3090 EVGA Hydro Copper��
����PCle ��չ������Ҳ����ͬʱ����ռ����ȴ���⣬������Ҫȷ�����㹻�Ŀռ�����չ GPU��
����Ҳ������Ҫʹ�ö����ͬ�ͺŵ� GPU ��ԭ���ǣ���Ҫ���þɵ� GPU���������������������û����ģ�����Щ GPU �ϵIJ��л���������dz���Ч����Ϊ�ٶ����� GPU ��Ҫ�ȴ������� GPU ������һ��ͬ���㣨ͨ�����ݶȸ��£���
����һ����˵û���á�NVLink �� GPU ֮��ĸ��ٻ���������ӵ��һ���䱸 128 �� GPU ���ϵ� GPU ��Ⱥʱ���������á���������ڱ� PCle ������˵��NVLink ����û���κ��洦��
����ʵ�ڲ��У��㻹������ë��ȥʹ����ѵ� GPU �Ʒ�������ͨ������ʱ�䡢�˻������ƣ�����֮����Ҫ���ѡ���ô�����ڲ�ͬ�˻�֮���л�ʹ�ðɣ�ֱ��������� GPU��
������������Gbits/s ���������ܼӿ��ٶȣ�֮ǰ����д��һƪ����ר����������£��������ڵĽ���������Ҫ�� EDR Infiniband��Ҳ�������� 50 GBit / s �������������۸����� 500 ��Ԫ���ҡ�
����������ʹ��Ӣ�ض� CPU��������Ҫ�� Kaggle �����д���ʹ�� CPU��������ˣ�ʹ�� AMD CPU Ҳ�ܰ��������ѧϰ���ԣ�AMD CPU ͨ���� Intel CPU �������Ҹ��á�
�����������õ� 4x GPU�����ߵ���ѡ�� Threadripper���ڴ�ѧ�ڼ�������ʹ�� Threadripper �����ʮ��ϵͳ�����Ƕ��������á����� 8x GPU ϵͳ��CPU �� PCIe / ϵͳ�Ŀɿ��Ա�ֱ�ӵ����ܻ��Լ۱ȸ���Ҫ��
����GTX XX90 ������ͨ��������˫ GPU ��������Ӣΰ�����Ǵ�����������Ӽ۸�������Ͽ���RTX 3090 �ƺ�ȡ���� RTX 3080 Ti��
������� GPU ֮����ڼ�϶�Ļ���ͨ���ܹ��ܺõ���ȴ���������ƻ���� 1-3 ���϶ȵ�Ч���������� GPU ֮��Ŀռ佫���� 10-30 ���϶ȵ�Ч������������˵ֻҪ GPU ֮�����пռ䣬ɢ�ȾͲ������⡣����� GPU ֮��û�пռ䣬����Ҫ�õ�ɢ������ƣ����ȣ����������������ˮ�䡢PCIe ��չ����
�����ʹ���оƬ��˵��AMD �� GPU �dz����㣺��ɫ�� FP16 ���ܺ��ڴ����������Ӣΰ�� GPU ��ȣ���ȱ���������Ļ��Ч�����£�AMD �����ѧϰ���ܸ�������ĵ;�����ѧ����Ҳδ�ܽ��������⡣�ﲻ������Ӳ�����ܣ�AMD GPU ����Զ����֮�������д��Ա�����һЩ���������ĵ�Ч�� AMD �������Ŀ��ƻ��� 2020 ���Ƴ��������ƺ������˻���ɡ�
����������� AMD �������Ƴ������������ĵ�Ӳ�����ܣ����ܶ���Ҳ��˵��������û�������� AMD GPU ���������Ҹ����ʹ���������������һЩ��⣬AMD ROCm ƽ̨�ս����죬���Ҷ� PyTorch Ҳʵ����ԭ��֧�֣���ɲ��ص��ġ�
������������������Ͳ������������ĵ����⣬������ʶ������һ�����⣺AMD �����������졣�������ʹ��Ӣΰ�� GPU ʱ������ʲô���⣬���� Google һ���ҵ�������������һ����˽�ܶ��ʹ�ü��ɺ�רҵ��ʿ�ľ�������AMD ���ⷽ��Ͳ���ô���������ˡ�
�����ñ�������������Ļ��������� Python �� Julia �Ĺ�ϵ��Julia ����ΪDZ�������ǿ�ѧ��������ĸ�������ԣ�����ʹ���������� Python ��ȫ�����Ტ�ۡ�����������Ϊ Python �����dz����ơ�
������ǰ���о���Ҫ�Ը��ڿ���ʵ���Ʒ����ҵ��ר�� GPU �������ʽϵ͡����о������Ͽ���һЩ����������ʺܵͣ��ɽ������о�������һЩ�������������ߵöࣨ�������롢���Խ�ģ����ͨ�����Ƕ���߹����˼�����������ʣ���������ǿ�ҽ����о�С�����ҵʹ�� slurm GPU ��Ⱥ�������˵Ļ��Ͳ����ˡ�
�������ڸ�����˵����Щ GPU ��Ҫ���κ� Tesla �����κ� Quadro �����κΡ���ʼ�桹GPU�����а��� Titan RTX �������ͺ�̩̹��
����ʲôҲ��˵�ˣ���û��Ǯ����ʹ�ø����Ʒ������Ѷ�ȣ�ֱ��������� GPU��
��������һ���߶˵ļ�����Ӿ���Ԥѵ��ģ�ͻ����������о���Ա���Ŀ� RTX 3090 �����������ɢ��ѹ��ס�İ汾���֣�����ҲҪ���ǵ�Դ���أ����������������ƪ���£����Եȴ�δ�������⣩��
����������ͨ NLP �о��ߣ�������о��������롢����ģ�͡�Ԥѵ���ȣ�һ�� RTX 3080 Ӧ�þ��ˡ�
������Ҫ�������ѧϰ��������Ц������Դӹ���һ�� RTX 3070 ��ʼ���������֮����Ȼ���鲻��������� RTX 3070 ���ۣ������Ŀ� RTX 3080����Զ��δ����������ѡ��·�߲�ͬ������Ҳ����ֱ仯��
���������������ѧϰ��RTX 2060 Super �dz���ɫ�����������ҪΪ��������Դ�������������� PCIe��16 ���ۣ���Դ�� 300W��һ�� GTX 1050Ti �����ʺϵġ�
������������ Tim Dettmers Ŀǰ�ǻ�ʢ�ٴ�ѧ�ڶ���ʿ����˶ʿ��ҵ����ʿ¬��ŵ��ѧ������ DIY ���ѧϰ������¯��������˵���������Ӧ�ò���İ������д�����µ����ѧϰ GPU ��������һֱ���˹�ע��Tim �� AI ��������Ҳʱ����Ӣΰ��Ŀ�����������¼��
����ֵ��һ����ǣ�Tim Dettmers �������������Ҳ�����ĵã����õ���˹̹����ѧ����ʢ�ٴ�ѧ���ش�ѧѧԺ�����ڻ�÷¡��ѧ�Լ�ŦԼ��ѧ�� offer ������ѡ���˻�ʢ�ٴ�ѧ���� 2018 ���һƪ���������У����ܽ����Լ���������ľ���ͼ��ɣ���Ҫ��ͬѧ����ȥ��һ�£������յ���˹̹����UCL��CMU��NYU��UW �IJ�ʿ offer�������ҵľ��顷 ��
|
 ������ҳ��
������ҳ�� 
 ����Ŀ
����Ŀ