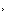|
邓肯捶地Nvidia 上个礼拜发布了迄今为止最强大的 DGX 服务器。120kW 机架规模系统使用将 72 个新型 Blackwell 加速器拼接在一起,形成一个本质上能够提供超过 1.4 exaFLOPS 性能的大型 GPU(无论如何,在 FP4 精度下)。
在这里,我们仔细研究机架规模系统,Nvidia 声称该系统可以支持大量训练工作量以及对高达 27 万亿个参数的模型进行推理,但目前还没有任何模型有这么大。
系统前端是四个 InfiniBand NIC(请注意机箱面板左侧和中心的四个 QSFP-DD 笼),它们构成了计算网络。该系统还配备了 BlueField-3 DPU,我们被告知它负责处理与存储网络的通信。
凭借两个 GB200 超级芯片和五个 NIC,我们估计每个节点的功耗为 5.4kW 到 5.7kW。绝大多数热量将通过直接芯片 (DTC) 液体冷却方式带走。Nvidia 在 GTC 上展示的 DGX 系统没有冷板,但我们确实看到了合作伙伴供应商的几个原型系统,例如联想的这个系统。
然而,与我们从 HPE Cray 或联想的Neptune系列中看到的以液体冷却所有设备的一些以 HPC 为中心的节点不同,Nvidia 选择使用传统的 40mm 风扇来冷却 NIC 和系统存储等低功耗外围设备。
在他的主题演讲中,首席执行官兼皮夹克爱好者 Jensen Huang 将 NVL72 描述为一个大型 GPU。这是因为所有 18 个超密集计算节点都通过位于机架中间的九个 NVLink 交换机堆栈相互连接。
Nvidia 的 HGX 节点也使用了相同的技术来使其 8 个 GPU 发挥作用。但是,NVL72 中的 NVLink 开关并不是像下面所示的 Blackwell HGX 那样将 NVLink 开关烘焙到载板上,而是一个独立的设备。
NVLink 交换机和计算底座均插入盲插背板,并具有超过 2 英里(3.2 公里)的铜缆布线。透过机架的背面,您可以隐约看到一大束电缆,它们负责将 GPU 连接在一起,以便它们可以作为一个整体运行。
坚持使用铜缆而不是光纤的决定似乎是一个奇怪的选择,特别是考虑到我们正在讨论的带宽量,但显然支持光学所需的所有重定时器和收发器都会在系统已经巨大的基础上再增加 20kW电力消耗。
这可以解释为什么 NVLink 交换机底座位于两个计算组之间,因为这样做可以将电缆长度保持在最低限度。
在机架的最顶部,我们发现了几个 52 端口Spectrum交换机 ― 48 个千兆位 RJ45 和四个 QSFP28 100Gbps 聚合端口。据我们所知,这些交换机用于管理和传输来自构成系统的各个计算节点、NVLink 交换机底座和电源架的流式遥测。
这些交换机的正下方是从 NVL72 前面可见的六个电源架中的第一个 - 三个位于机架顶部,三个位于底部。我们对它们了解不多,只知道它们负责为 120kW 机架提供电力。
根据我们的估计,六个 415V、60A PSU 就足以满足这一要求。不过,Nvidia 或其硬件合作伙伴可能已经在设计中内置了一定程度的冗余。这让我们相信它们的运行电流可能超过 60A。我们已向 Nvidia 询问有关电源架的更多详细信息;我们会让您知道我们的发现。
不管他们是怎么做的,电力都是由沿着机架背面延伸的超大规模直流母线提供的。如果仔细观察,您可以看到母线沿着机架中间延伸。
当然,冷却 120kW 的计算并不是小事。但随着芯片变得越来越热和计算需求不断增长,我们看到越来越多的比特仓(包括 Digital Realty 和 Equinix)扩大了对高密度 HPC 和 AI 部署的支持。
就 Nvidia 的 NVL72 而言,计算交换机和 NVLink 交换机均采用液体冷却。据 Huang 介绍,冷却剂以每秒 2 升的速度进入 25 摄氏度的机架,离开时温度升高 20 度。
英伟达表示,其 Blackwell 部件,包括机架规模系统,将于今年晚些时候开始投放市场。
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。
|
 返回首页
返回首页 
 栏目
栏目